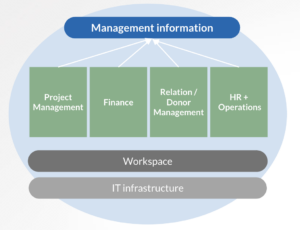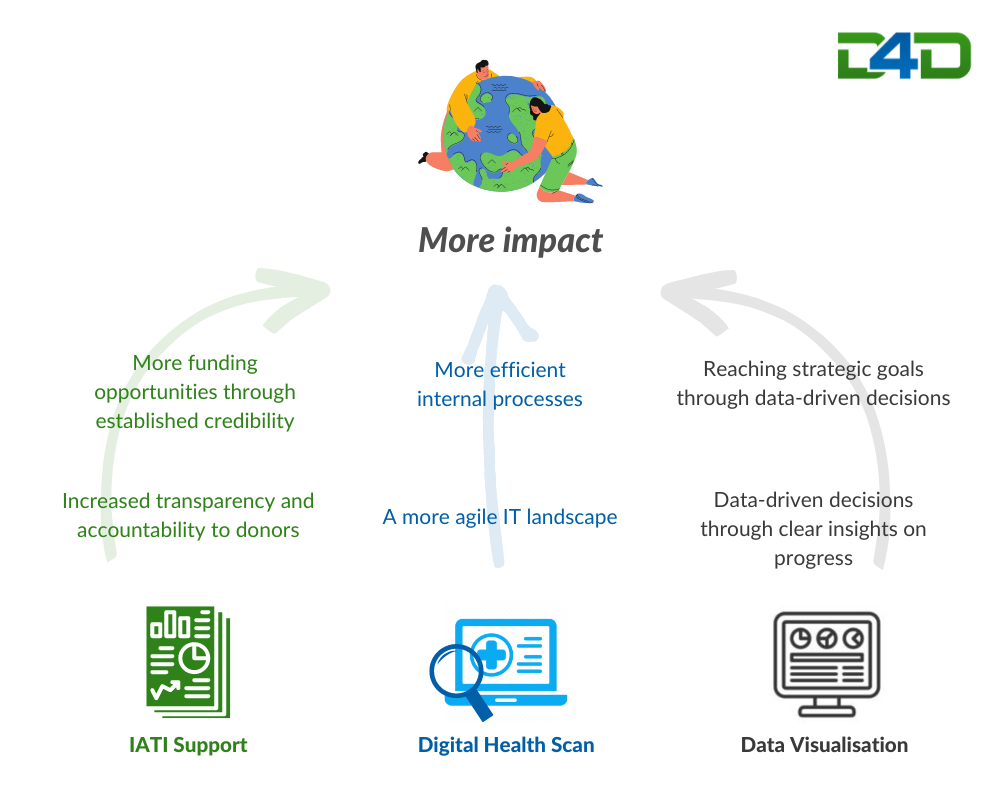
“The greatest added value of D4D is in their role as a knowledge partner, where they really roll up their sleeves to take KPIs and measurement plans to a higher level. They know how to separate sense and nonsense and bring order to existing processes and systems. I am really impressed with the knowledge and skills of the people at D4D that I have worked with so far.”

D4D has helped us look critically at our internal processes and systems and make them future-proof. They adapted their services where needed and left the choices up to us. By coordinating this in a step-by-step project, D4D was super helpful to keep us on track, create ownership in our team and get things done.

"D4D first selected well-suited products for our financial and project administrative systems. Then they counselled the development and fine tuning of the system for Hivos and helped prepare to set it up. D4D has a very capable and committed staff that are very pleasant to deal with. During the entire process they really started to understand the Hivos culture and the way that translates to the result of our services. I would definitely recommend D4D!"